Another long run of Webindex was done to test changes made since beta-2 and it went well. This run performed much better than the previous the previous long run of Webindex. The experiment was run on 21 EC2 m3-xlarge nodes (20 worker nodes). Each node has 4 cores and 15G of RAM. 273.6 million web pages and 3.54 billion links were processed from 8,000 common crawl files (each file is around 330M). It took around 80 hours to load the files resulting in a rate of ~950 web page/sec and ~12,292 links/sec.
This blog post outlines the changes to Fluo, Fluo Recipes, and Webindex that made this long run so much better than the last one. For anyone writing applications on Fluo, the changes to Webindex that resulted in improvements may be of interest. Unreleased versions of Fluo and Fluo Recipes were used for this test, so the improvements are not easily available to users yet. However we hope to release new versions soon.
Rate limited page loading
The plot below shows how many transactions per second were executed by different observers. Please refer to the overview in the last post for a description of the observers and see the previous plots. The transactions per second is very even compared to the last run. The document load rate was limited to a maximum of 1,000 pages per second. There was no limit in the last run, it just ran as fast as it could.
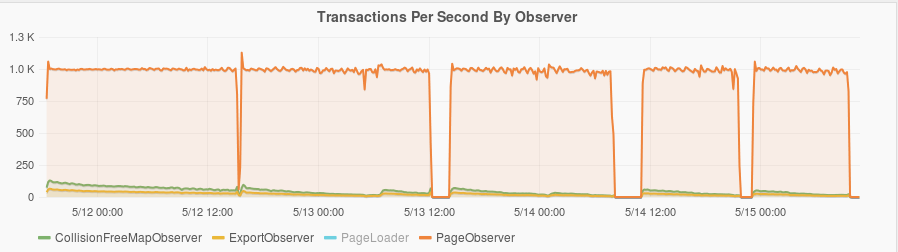
The PageLoader is not show in the plot above because of a bug with it in the historical view. In the recent Grafana view it plotted fine and basically mirrored the PageObserver.
The ability to rate limit page loading was added in webindex-70. For this test run 20 Spark load task were run, each limited to 50 pages per second. The latest code can sustain much higher rates initially (see this comment). However once a lot of data builds up, compactions and scans in Accumulo start taking more CPU. A rate of 1,000 pages per second was chosen as something that could be sustained over multiple days. The CPU plots below show that in the beginning there is idle CPU to spare, but that does not last.
CPU Utilization
In order to get higher throughput changes were made to reduce CPU usage and evenly spread CPU usage across the cluster. The following plot shows the CPU usage of all nodes across the cluster during the test. Unfortunately this data was not kept for the previous run. One issue that caused problems in the previous run was hotpots, where one node was swamped while others were under utilized. In this run the utilization across the cluster was fairly uniform.
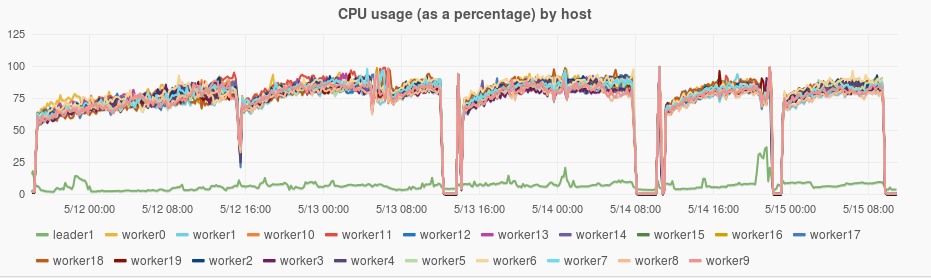
The following evenly spread computation :
- A short hash was appended to URLs used as the row key for pages. This spread web pages evenly across the cluster. These changes were made in webindex-49 and fluo-recipes-45.
- The webindex query table schema was changed in webindex-71 to allow large rows to split. Before this change compactions of large tablets that could not split were causing uneven CPU utilization.
The following reduced CPU usage :
- The two Accumulo tables (Fluo and query table) were configured to use Snappy instead of GZip.
- In fluo-623 the Fluo iterators that run in Accumulo were optimized to sometimes seek. This resulted in scanning less data in Accumulo to execute transactions and find notifications.
- In webindex-54 parsing links was sped up, using less CPU.
- Accumulo 1.7.1 was used which has ACCUMULO-4066. This made processing conditional mutations less CPU intensive.
There were 20 worker nodes and 1 master node. The master node was running the namenode, zookeeper, resource manager, Accumulo master, Grafana, and InfluxDB. The master node was normally lightly loaded. However, at one point InfluxDB was burning lots of CPU for an extended period. This impacted the namenode, which impacted the entire cluster. Not sure what InfluxDB was doing, maybe something like a compaction. May put it on its own node in future test.
The following table shows how the 8,000 files were loaded by 5 spark jobs. After each Spark job completed the two tables were compacted. Compacting the query table prevented expensive compactions from occurring during the next load. Compacting the Fluo table cleaned up transaction bookkeeping data. The compactions explain why the CPU utilization is low when the jobs first start.
| Num files | Start time | Duration |
|---|---|---|
| 2000 | 5/11 22:32:41 | 20.8h |
| 2000 | 5/12 19:34:38 | 20.7h |
| 2000 | 5/13 18:19:09 | 17.7h |
| 1000 | 5/14 15:09:43 | 10.5h |
| 1000 | 5/14 03:10:13 | 10.5h |
Preventing YARN from killing workers
In the previous run Fluo worker processes were constantly being killed by YARN for exceeding memory limits. This would cause transactions to have to be rolled back. With the new asynchronous commit changes discussed below a lot of committing transactions could be in flight. Frequently killing processes with lots of committing transactions would cause lots of rollbacks.
This problem was remedied in fluo-593 and zetten-139. For this run the workers were given 5.5G with 1.5G reserved. With these settings no workers were killed by YARN. When workers are killed it causes upward spikes in the memory plots. There are no spikes of individual workers like this in the memory plots below.
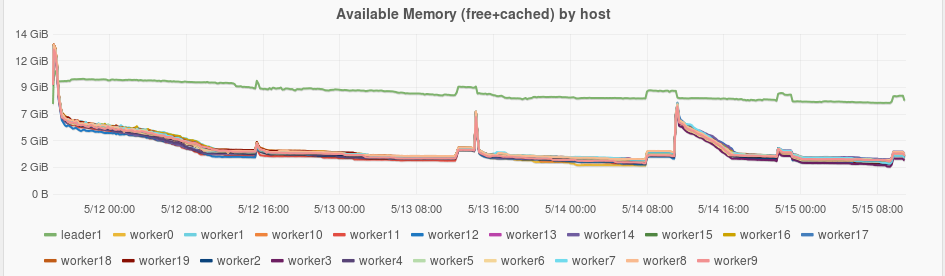
Twill reserved memory was set by adding the following to yarn-site.xml. fluo-671 was opened to investigate a better way of setting this.
<property>
<name>twill.java.reserved.memory.mb</name>
<value>1536</value>
</property>
The following was set in fluo.properties.
io.fluo.worker.max.memory.mb=5632
This resulted in workers running with a max heap size of 4096M. The processes will grow larger than 4096M, but will not be killed by YARN unless exceeding 5632M.
Asynchronous commits
In fluo-593 commit processing was rewritten using an asynchronous model. There is no longer a single thread walking each transaction through the commit steps. Instead many transactions are put on a queue for each step and processed by a few threads. This allows many more transactions to be concurrently committing. With this model a temporary pause or high CPU load on a tablet server does not lower throughput. Before this change, when tservers spiked to 100% this would impact many committing transactions and the threads running those transactions. Those threads would wait. This would lead to lower utilization across the cluster.
The plot below shows the number of transactions committing. As the CPU utilization increase, so does the number of committing transactions. With the high CPU utilization it takes longer for individual transactions to commit, but throughput is maintained.
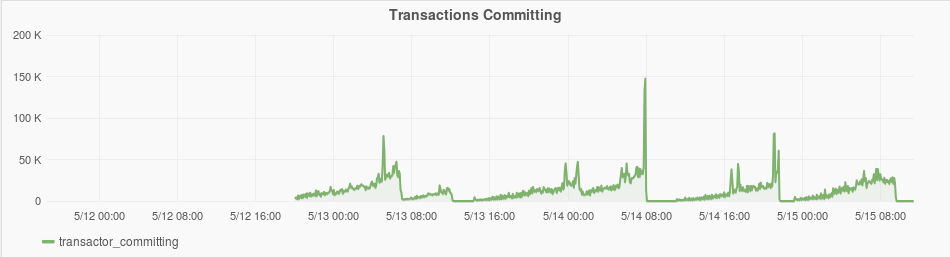
Unfortunately the plot does not have all data because it was based on recent data which ages off. The historical plots for committing transactions is not yet implemented. See fluo-653.
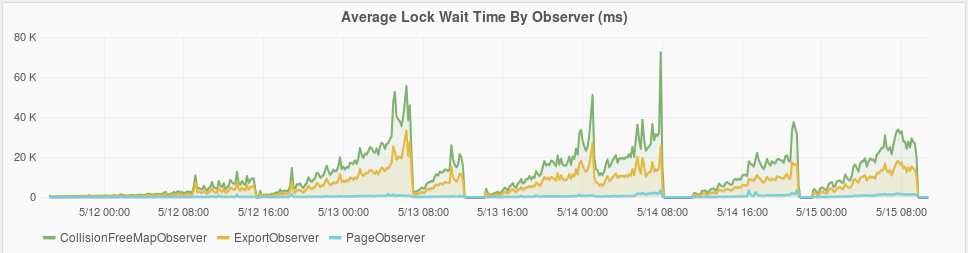
Asynchronous commits offer higher throughput but also increase the commit time of individual transactions. As outlined in fluo-650 this can lead to increased lock wait time when one transaction is waiting on another. This problem was partially solved by fluo-654 which executes older notifications first. For Webindex, executing older transactions first works well for the page data. However for the Collision Free Maps and Export Queue buckets that are always being updated, it does not work so well. A transaction processing these buckets will usually have lock wait. The number of buckets was set at half the total number of worker threads with the thought that this would usually leave some threads to process pages. Not sure if this was helpful. A better solution to fluo-650 is needed. Below is a plot of lock wait time.
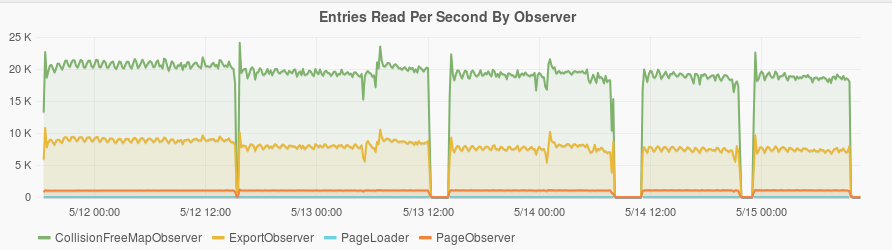
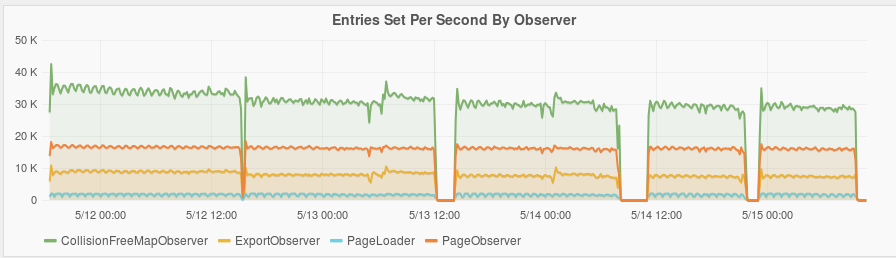
Read and Write plots
Below are plots of the amount data read and written per second by different Observers.
Accumulo Settings
The following were executed in the Accumulo shell after initializing Fluo but before starting the first Spark load job.
config -t webindex -s table.compaction.major.ratio=1.75
config -t webindex -s table.file.compress.blocksize.index=256K
config -t webindex -s table.file.compress.blocksize=64K
config -t webindex -s table.file.compress.type=snappy
config -t webindex_search -s table.file.compress.type=snappy
config -t webindex_search -s table.split.threshold=512M
config -t accumulo.metadata -s table.durability=flush
config -t accumulo.root -s table.durability=flush
config -s tserver.wal.replication=2
config -s table.file.replication=2
Fluo used the webindex table. A blocksize of 64k was selected to speed up
random lookups a bit. A compaction ratio of 1.75 was chosen so that the Fluo
table would compact more frequently. Compactions of the Fluo table run the
Fluo garbage collection iterator.
Webindex uses the webindex_search table for queries and Fluo exports to it.
This table uses real data like domain names and URLs, therefore the data does
not spread evenly. Lowering the split from the default of 1G to 512M makes
tablets with popular domains or URLs split and spread across the cluster
sooner.
Data replication was set to 2 because the cluster did not have a lot of space and the default of 3 may have filled it up.
The Accumulo tserver were configured with a data cache of 3G and an index cache of 512M.
At some point later in the test, the number of compaction threads in Accumulo was adjusted from 3 to 2. This was done because there were only 4 cores and having compactions use most of them could be disruptive.
Fluo Settings
Fluo was configured with 128 threads per worker and 20 workers.
For the test the following was set in fluo.properties. This settings determines the maximum amount of transactions that will be held in memory to commit asynchronously.
io.fluo.impl.tx.commit.memory=104857600
Webindex settings
Webindex was configured with the following settings.
numTablets: 60
numBuckets: 1020
Each type of data started with 60 tablets. The types of data are page data, url inlink counts, domain url counts, and the export queue. 1,020 is multiple of 60 giving each tablet the same number of buckets. With 60 tablets, each tablet server started off with 3 tablets per data type. Some of the data types split as the test ran.
Final Data Size
After loading all of the data the two tables were compacted. The size of the tables is shown below.
root@instance16> du webindex
291,525,943,501 [webindex]
root@instance16> du webindex_search
271,106,371,976 [webindex_search]
Postmortem analysis of the RFiles from this test run lead to work on ACCUMULO-1124 and ACCUMULO-4314.
Software used
View all posts in the news archive