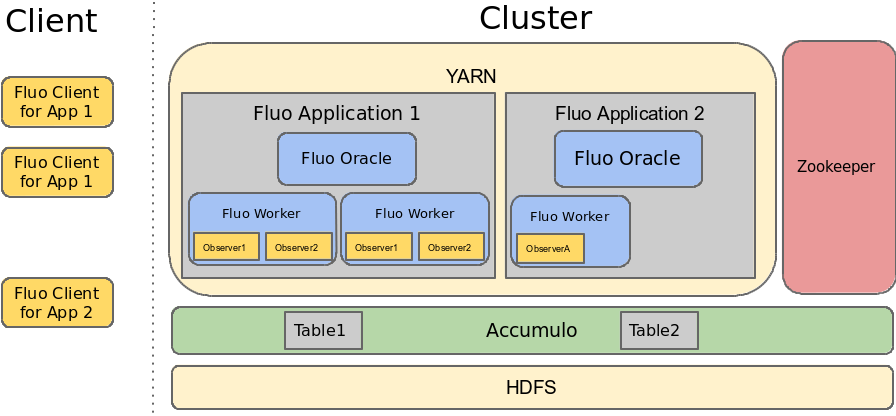
Fluo Application
A Fluo application maintains a large scale computation using a series of small transactional updates. Fluo applications store their data in a Fluo table which has a similar structure (row, column, value) to an Accumulo table except that a Fluo table has no timestamps. A Fluo table is implemented using an Accumulo table. While you could scan the Accumulo table used to implement a Fluo table using an Accumulo client, you would read extra implementation-related data in addition to your data. Therefore, developers should only interact with the data in a Fluo table by writing Fluo client or observer code:
- Clients ingest data or interact with Fluo from external applications (REST services, crawlers, etc).
- Observers are run by Fluo workers and trigger a transaction when a requested column is modified in the Fluo table.
Multiple Fluo applications can run on a cluster at the same time. Each Fluo application runs as a Hadoop YARN application and can be stopped, started, and upgraded independently. Fluo applications consist of an oracle process and a configurable number of worker processes:
- The Oracle process allocates timestamps for transactions. While only one Oracle is required, Fluo can be configured to run extra Oracles that can take over if the primary Oracle fails.
- Worker processes run user code (called observers) that perform transactions. All workers run the same observers. The number of worker instances are configured to handle the processing workload.
Fluo Dependencies
Fluo requires the following software to be running on the cluster:
- Accumulo - Fluo stores its data in Accumulo and uses Accumulo’s conditional mutations for transactions.
- Hadoop - Each Fluo application run its oracle and worker processes as Hadoop YARN applications. HDFS is also required for Accumulo.
- Zookeeper - Fluo stores its metadata and state information in Zookeeper. Zookeeper is also required for Accumulo.