Fluo Tour: Row Locking
Tour page 22 of 28
Fluo relies on Accumulo’s conditional mutations to implement cross node transactions. Conditional mutations lock entire rows on the server side when checking conditions. These row locks can impact the performance of your transactions, so it’s something to be aware of when designing a schema.
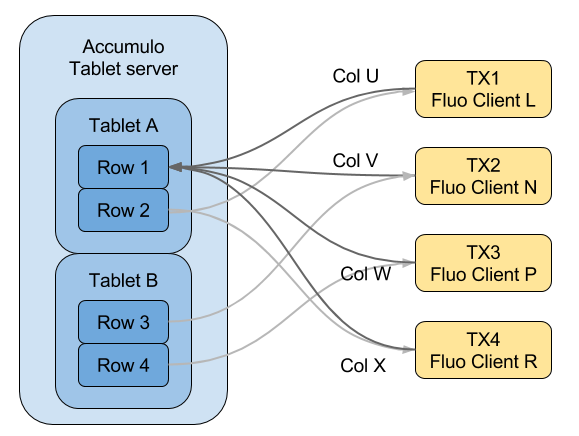
For example, the following illustration shows multiple Fluo clients executing
transactions. These transactions update different columns in the same row.
The transactions will not collide, however they may end up waiting on each
other because Accumulo locks Row 1 to process each update.
Determining whether this problem will impact you depends on your schema and the probability of concurrent updates. Mitigating action is only needed if the following criteria are met.
- Many transactions will update separate columns in a row.
- Those transactions are very likely to run concurrently.
If both of the conditions above are met then transactions will likely wait
unnecessarily. One simple way to avoid the wait is to move some of the
information that was in the column into the row. In the example above the
information in the column could be appended to the row. Then the transactions
would be updating rows Row 1:U, Row 1:V, Row 1:W, and Row 1:X. Since
these are separate rows, lock contention is avoided in Accumulo tablet servers.
Example
The following code demonstrate the impact of schema design on performance. The code adds lots of edges to a single node in a graph using many transactions and threads. All of the edges are added to a single row.
These performance problems may not occur on a single node with a single client, because Fluo clients batch a lot of operations related to committing. To make the problem more apparent on a single node, the following code creates three clients and three loaders.
public static class EdgeLoader implements Loader {
private String node1;
private String node2;
public EdgeLoader(String node1, String node2) {
this.node1 = node1;
this.node2 = node2;
}
@Override
public void load(TransactionBase tx, Context ctx) throws Exception {
tx.set(node1, new Column("edge", node2), "");
}
}
private static void exercise(MiniFluo mini, FluoClient client) {
String node1 = "n00000";
long t1 = System.currentTimeMillis();
try (LoaderExecutor le1 = client.newLoaderExecutor();
FluoClient client2 = FluoFactory.newClient(mini.getClientConfiguration());
LoaderExecutor le2 = client2.newLoaderExecutor();
FluoClient client3 = FluoFactory.newClient(mini.getClientConfiguration());
LoaderExecutor le3 = client2.newLoaderExecutor()) {
int start = 1;
for(LoaderExecutor le : Arrays.asList(le1, le2, le3)) {
for (int i = 1; i < 10000; i++) {
String node2 = String.format("%05d", i+start);
le.execute(new EdgeLoader(node1, node2));
}
start+=10000;
}
}
long t2 = System.currentTimeMillis();
System.out.println(t2 - t1);
}
Try running the code above and note the time. Then change the load function to the following and run the code again. You should see a significant decrease in the time it takes. The change below spreads the edges over many rows.
@Override
public void load(TransactionBase tx, Context ctx) throws Exception {
tx.set(node1+":"+node2, new Column("edge", ""), "");
}